Средства¶
Звучит достаточно сложно для того, чтобы начать декомпозировать проект на компоненты.
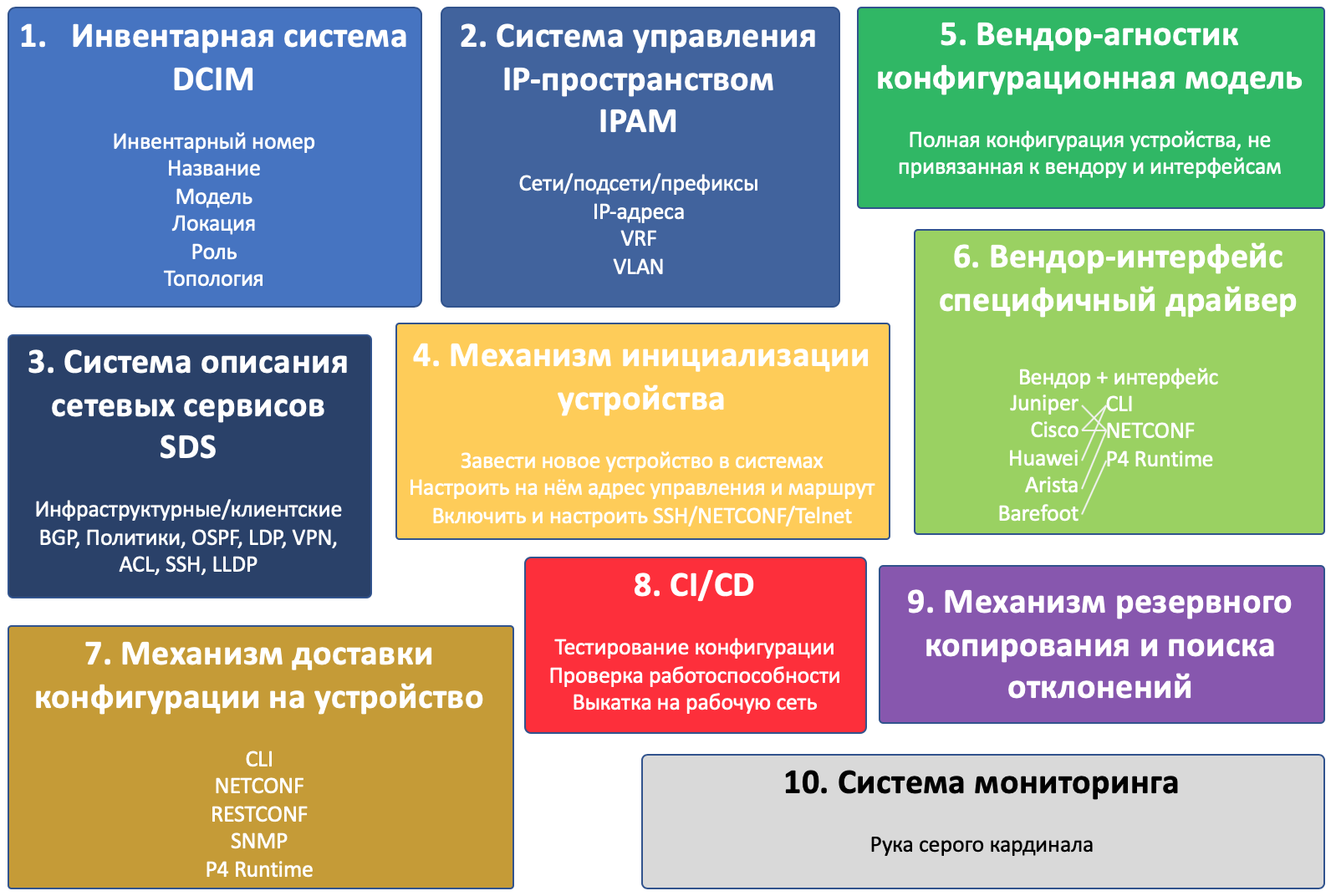
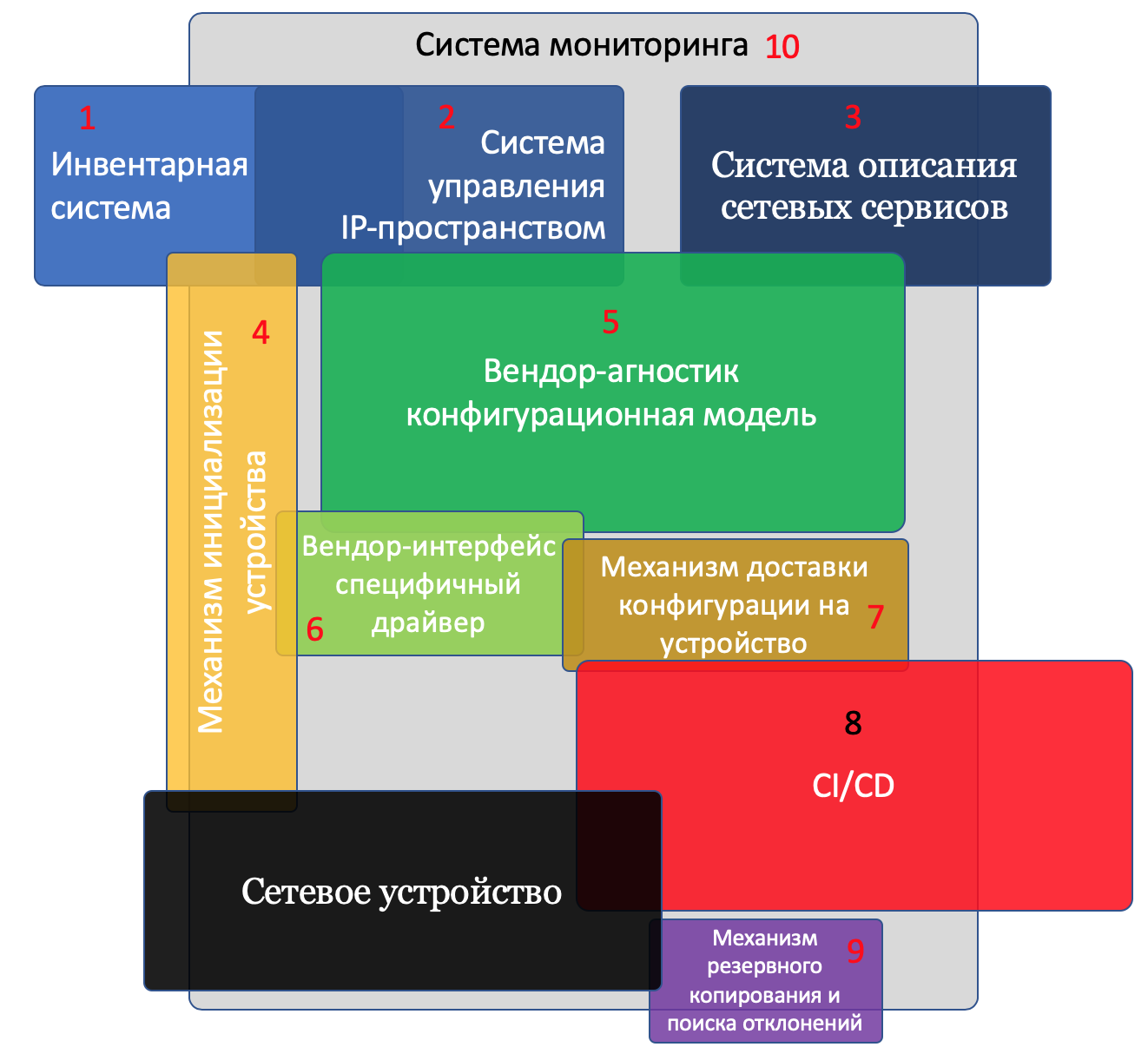
И будет их десять:
Инвентарная система
Система управления IP-пространством
Система описания сетевых сервисов
Механизм инициализации устройств
Вендор-агностик конфигурационная модель
Вендор-интерфейс специфичный драйвер
Механизм доставки конфигурации на устройство
CI/CD
Механизм резервного копирования и поиска отклонений
Система мониторинга
Это, кстати, пример того, как менялся взгляд на цели цикла - в черновике компонентов было 4.
Компонент 1. Инвентарная система¶
Для наших задач в ней мы будем хранить следующую информацию про устройство:
- Инвентарный номер
- Название/описание
- Модель (Huawei CE12800, Juniper QFX5120 итд)
- Характерные параметры (платы, интерфейсы итд)
- Роль (Leaf, Spine, Border Router итд)
- Локацию (регион, город, дата-центр, стойка, юнит)
- Интерконнекты между устройствами
- Топологию сети

В ней же мы будем хранить виртуальные сетевые устройства, например виртуальные маршрутизаторы или рут-рефлекторы. Можем добавить DNS-сервера, NTP, Syslog и вообще всё, что так или иначе относится к сети.
Компонент 2. Система управления IP-пространством¶
Для наших задач в ней мы будем хранить следующую информацию:
- VLAN
- VRF
- Сети/Подсети
- IP-адреса
- Привязка адресов к устройствам, сетей к локациям и номерам VLAN

Опять же понятно, что мы хотим быть уверены, что, выделяя новый IP-адрес для лупбэка ToR’а, мы не споткнёмся о то, что он уже был кому-то назначен. Или что один и тот же префикс мы использовали дважды в разных концах сети.
Но как это поможет в автоматизации?
Легко.
Компонент 3. Система описания сетевых сервисов¶
Если первые две системы хранят переменные, которые ещё нужно как-то использовать, то третья описывает для каждой роли устройства, как оно должно быть настроено.
Стоит выделить два разных типа сетевых сервисов:
- Инфраструктурные
- Клиентские
- физические и логические интерфейсы (тег/антег, mtu)
- IP-адреса и VRF (IP, IPv6, VRF)
- ACL и политики обработки трафика
- Протоколы (IGP, BGP, MPLS)
- Политики маршрутизации (префикс-листы, коммьюнити, ASN-фильтры).
- Служебные сервисы (SSH, NTP, LLDP, Syslog…)
- Итд.
Как именно мы это будем делать, я пока ума не приложу. Разберёмся в отдельной статье.

Если чуть ближе к жизни, то мы могли бы описать, что Leaf-коммутатор должен иметь BGP-сессии со всем подключенными Spine-коммутаторами, импортировать в процесс подключенные сети, принимать от Spine-коммутаторов только сети из определённого префикса. Ограничивать CoPP IPv6 ND до 10 pps итд. В свою очередь спайны держат сессии со всеми подключенными лифами, выступая в качестве рут-рефлекторов, и принимают от них только маршруты определённой длины и с определённым коммунити.
Компонент 4. Механизм инициализации устройства¶
Под этим заголовком я объединяю множество действий, которые должны произойти, чтобы устройство появилось на радарах и на него можно было попасть удалённо.
- Завести устройство в инвентарной системе.
- Выделить IP-адрес управления.
- Настроить базовый доступ на него: Hostname, IP-адрес управления, маршрут в сеть управления, пользователи, SSH-ключи, протоколы - telnet/SSH/NETCONF
Тут существует три подхода:
- Полностью всё вручную. Устройство привозят на стенд, где обычный органический человек, заведёт его в системы, подключится консолью и настроит. Может сработать на небольших статических сетях.
- ZTP - Zero Touch Provisioning. Железо приехало, встало, по DHCP получило себе адрес, сходило на специальный сервер, самонастроилось.
- Инфраструктура консольных серверов, где первичная настройка происходит через консольный порт в автоматическом режиме.
Про все три поговорим в отдельной статье.

Компонент 5. Вендор-агностик конфигурационная модель¶
До сих пор все системы были разрозненными лоскутами, дающими переменные и декларативное описание того, что мы хотели бы видеть на сети. Но рано или поздно, придётся иметь дело с конкретикой.
На этом этапе для каждого конкретного устройства примитивы, сервисы и переменные комбинируются в конфигурационную модель, фактически описывающую полную конфигурацию конкретного устройства, только в вендоронезависимой манере.
Что даёт этот шаг? Почему бы сразу не формировать конфигурацию устройства, которую можно просто залить?
На самом деле это позволяет решить три задачи:
- Не подстраиваться под конкретный интерфейс взаимодействия с устройством. Будь то CLI, NETCONF, RESTCONF, SNMP - модель будет одинаковой.
- Не держать количество шаблонов/скриптов по числу вендоров в сети, и в случае изменения дизайна, менять одно и то же в нескольких местах.
- Загружать конфигурацию с устройства (бэкапа), раскладывать её в точно такую же модель и непосредственно сравнивать между собой целевую конфигурацию и имеющуюся для вычисления дельты и подготовки конфигурационного патча, который изменит только те части, которые необходимо или для выявления отклонений.

В результате этого этапа мы получаем вендоронезависимую конфигурацию.
Компонент 6. Вендор-интерфейс специфичный драйвер¶
Не стоит тешить себя надеждами на то, что когда-то настраивать циску можно будет точно так же, как джунипер, просто отправив на них абсолютно одинаковые вызовы. Несмотря на набирающие популярность whitebox’ы и на появление поддержки NETCONF, RESTCONF, OpenConfig, конкретный контент, который этими протоколами доставляется, отличается от вендора к вендору, и это одно из их конкурентных отличий, которое они так просто не сдадут.
Это примерно точно так же, как OpenContrail и OpenStack, имеющие RestAPI в качестве своего NorthBound-интерфейса, ожидают совершенно разные вызовы.
Итак, на пятом шаге вендоронезависимая модель должна принять ту форму, в которой она поедет на железо.
И здесь все средства хороши (нет): CLI, NETCONF, RESTCONF, SNMP простихоспаде.
Поэтому нам понадобится драйвер, который результат предыдущего шага переложит в нужный формат конкретного вендора: набор CLI команд, структуру XML.

Компонент 7. Механизм доставки конфигурации на устройство¶
Конфигурацию-то мы сгенерировали, но её ещё нужно доставить на устройства - и, очевидно, не руками.
Во-первых, перед нами тут встаёт вопрос, какой транспорт будем использовать? А выбор на сегодняшний день уже не маленький:
- CLI (telnet, ssh)
SNMP- NETCONF
- RESTCONF
- REST API
- OpenFlow (хотя он из списка и выбивается, поскольку это способ доставить FIB, а не настройки)
Давайте тут расставим точки над ё. CLI - это легаси. SNMP… кхе-кхе.
RESTCONF - ещё пока неведомая зверушка, REST API поддерживается почти никем. Поэтому мы в цикле сосредоточимся на NETCONF.
На самом деле, как уже понял читатель, с интерфейсом мы к этому моменту уже определились - результат предыдущего шага уже представлен в формате того интерфейса, который был выбран.
Во-вторых, а какими инструментами мы будем это делать?
Тут выбор тоже большой:
- Самописный скрипт или платформа. Вооружимся ncclient и asyncIO и сами всё сделаем. Что нам стоит, систему деплоймента с нуля построить?
- Ansible с его богатой библиотекой сетевых модулей.
- Salt с его скудной работой с сетью и связкой с Napalm.
- Собственно Napalm, который знает пару вендоров и всё, до свиданья.
- Nornir - ещё один зверёк, которого мы препарируем в будущем.
Здесь ещё фаворит не выбран - будем шупать.
Что здесь ещё важно? Последствия применения конфигурации.
Успешно или нет. Остался доступ на железку или нет.
Кажется, тут поможет commit с подтверждением и валидацией того, что в устройство сгрузили. Это в совокупности с правильной реализацией NETCONF значительно сужает круг подходящих устройств - нормальные коммиты поддерживают не так много производителей. Но это просто одно из обязательных условий в RFP. В конце концов никто не переживает, что ни один российский вендор не пройдёт под условие 32*100GE интерфейса. Или переживает?

Компонент 8. CI/CD¶
К этому моменту у нас уже готова конфигурация на все устройства сети.
Я пишу «на все», потому что мы говорим о версионировании состояния сети. И даже если нужно поменять настройки всего лишь одного свитча, просчитываются изменения для всей сети. Очевидно, они могут быть при этом нулевыми для большинства узлов.
Но, как уже было сказано, выше, мы же не варвары какие-то, чтобы катить всё сразу в прод.
Сгенерированная конфигурация должна сначала пройти через Pipeline CI/CD.
CI/CD означает Continuous Integration, Continuous Deployment. Это подход, при котором команда не раз в полгода выкладывает новый мажорный релиз, полностью заменяя старый, а регулярно инкрементально внедряет (Deployment) новую функциональность небольшими порциями, каждую из которых всесторонне тестирует на совместимость, безопасность и работоспособность (Integration).
Для этого у нас есть система контроля версий, следящая за изменениями конфигурации, лаборатория, на которой проверяется не ломается ли клиентский сервис, система мониторинга, проверяющая этот факт, и последний шаг - выкатка изменений в рабочую сеть.
За исключением отладочных команд, абсолютно все изменения на сети должны пройти через CI/CD Pipeline - это наш залог спокойной жизни и длинной счастливой карьеры.

Компонент 9. Система резервного копирования и поиска отклонений¶
Ну про бэкапы лишний раз говорить не приходится.
Будем просто их по крону или по факту изменения конфигурации в гит складывать.
А вот вторая часть поинтереснее - за этими бэкапами кто-то должен приглядывать. И в одних случаях этот кто-то должен пойти и вертать всё как было, а в других, мяукнуть кому-нибудь, о том, что непорядок.
Например, если появился какой-то новый пользователь, который не прописан в переменных, нужно от хака подальше его удалить. А если новое файрвольное правило - лучше не трогать, возможно кто-то просто отладку включил, а может новый сервис, растяпа, не по регламенту прописал, а в него уже люди пошли.
От некой небольшой дельты в масштабах всей сети мы всё равно не уйдём, несмотря на любые системы автоматизации и стальную руку руководства. Для отладки проблем всё равно никто конфигурацию не будет вносить в системы. Тем более, что их может даже не предусматривать модель конфигурации.
Например, файрвольное правило для подсчёта числа пакетов на определённый IP, для локализации проблемы - вполне рядовая временная конфигурация.

Компонент 10. Система мониторинга¶
Сначала я не собирался освещать тему мониторинга - всё же объёмная, спорная и сложная тема. Но по ходу дела оказалось, что это неотъемлемая часть автоматизации. И обойти её стороной хотя бы даже без практики нельзя.
Развивая мысль - это органическая часть процесса CI/CD. После выкатки конфигурации на сеть, нам нужно уметь определить, а всё ли с ней теперь в порядке.
И речь не только и не столько о графиках использования интерфейсов или доступности узлов, сколько о более тонких вещах - наличии нужных маршрутов, атрибутов на них, количестве BGP-сессий, OSPF-соседей, End-to-End работоспособности вышележащих сервисов.
А не перестали ли складываться сислоги на внешний сервер, а не сломался ли SFlow-агент, а не начали ли расти дропы в очередях, а не нарушилась ли связность между какой-нибудь парой префиксов?
В отдельной статье мы поразмышляем и над этим.